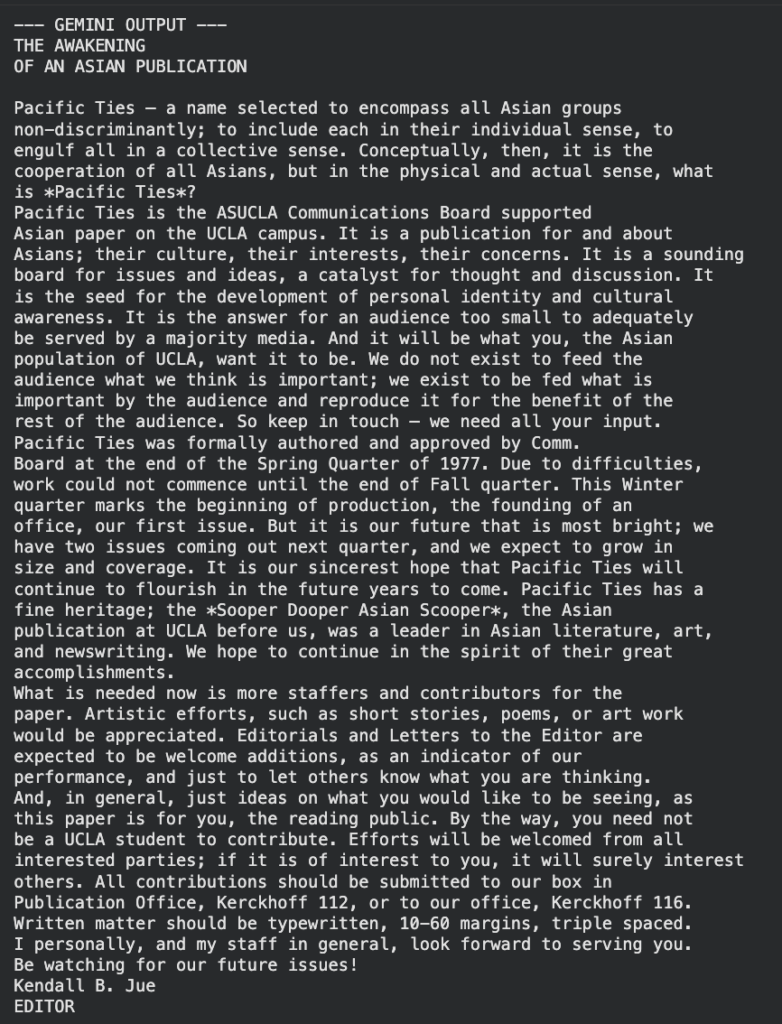
An Introduction to Pacific Ties
Written by the editor of Pacific Ties, Kendall B. Jue, this artifact details the origins of the newsmagazine. As this artifact is the first issue of the newsmagazine, the letter acknowledges the history of Asian American journalism at UCLA and the significance of the paper being supported officially by the ASUCLA Communications Board. The letter opens with an explanation of the name “Pacific Ties”, which was chosen to “encompass all Asian groups non-discriminantly; to include each in their individual sense, to engulf all in a collective sense”. This distinction is important to note, as the publication’s mission is to give voice to marginalized groups, even within the Asian American community itself.
Interestingly, the editor refers to the magazine as the “Asian paper” on campus, a definition which has now expanded to Asian Pacific Islander Desi American (APIDA) to further highlight the diversity of the community. This artifact establishes the foundation for the archive, framing the magazine as both a cultural and political platform for student voices during a pivotal moment in Asian American history.
Optical character recognition (OCR): Tesseract vs. gemini
In the context of this archive, there was a clear use case for OCR to increase legibility and readability of the scanned pages; however, our analyses proved that both manual and AI methods are not yet suitable on their own for archival purposes. To perform OCR, we used Tesseract and prompted Google’s Gemini, then compared the resulting Word Error Rates (WER) and Character Error Rates (CER).
While both methods were similarly straightforward in the preprocessing steps, Gemini was slightly simpler than Tesseract as it did not require a binarized image, instead taking in the original photo. Additionally, the image was cropped to ensure only the desired text was being processed, as there were often additional advertisements or callouts in the page’s layout
For error detection in both methods, the original text had to be converted manually, which was a tedious process that involved reading the text and typing the words as they appeared. Furthermore, with a WER and a CER of 18.82%, Gemini performed marginally better than Tesseract, which produced a WER and CER of 19.69%.
These results indicate that both methods have a fairly high error rate, given the context of the task. With an error rate of about 20%, this would imply that about one in every five words would be incorrect for the WER and one in every five characters would be incorrect for the CER. Given the task of transcribing an article or other written work, these errors compound and introduce unintended bias in the interpretation and understanding of the text.

A Brief History of Asian American Publications
This article, written by Dee Hayashi, situates Pacific Ties within the broader context of other Asian American publications, namely Gidra, the San Francisco Journal, and the Sooper Dooper Asian Scooper. As a result, readers gain a greater understanding of the need for a publication by and for Asian Americans to become educated on issues impacting the community to facilitate productive change. Additionally, the article explores how Asian American publications have evolved to grow with their audience, choosing to either focus on issues impacting specific ethnic groups or sharing their political perspectives. For both types of publications, the article adds that their mission is impacted by a lack of financial resources and volunteers.
With this, Pacific Ties is uniquely positioned in its support from the ASUCLA Communications Board, providing a sense of stability that past publications lacked. This article reinforces the idea that storytelling and self-representation are essential tools in resisting marginalization, a theme present throughout the archive. Together, these publications illustrate how APIDA communities have continually created their own spaces to challenge dominant narratives.
Topic modeling: Latent Dirichlet Allocation (LDA) vs. gemini
Performed on a corpus containing all of the artifacts, topic modeling could be a useful way to extract the prominent themes, effectively creating labels to be used in tagging the artifacts.
For the manual analysis, we performed LDA and created labels based on the results. For example, Topic 3 produced words such as “bakke, court, admissions, case, decision, programs, minority, racial, preferential”, which we labeled as “Affirmative Action” because of the focus on the landmark case of Regents of the University of California v. Bakke that established affirmative action. For the AI analysis, we prompted Gemini to create scholarly labels for each of the topics from LDA. This proved to be useful in interpreting the LDA results, with many of the topics aligning well with archival themes, such as Topic 2 clearly reflecting “Korean American Youth and Community Engagement” and Topic 6 reflecting “Chinese Cultural Performances and Events”. The AI-generated labels struggled when the topics themselves contained ambiguous or irrelevant words, such as “hair” in Topic 0 and “00” in Topic 6.
To quantitatively compare the manual and AI results, we calculated the Jaccard similarity between the LDA topics and the generated labels. The average similarity score was 0.17, which indicates limited overlap between the LDA keywords and the AI-generated labels. This reflects how LDA is effective in detecting patterns across a corpus, but Gemini and other AI labeling tools are better at generating interpretable, human-friendly labels. However, the low Jaccard scores indicate that AI cannot fully replace human judgment for tagging or labeling archival artifacts, especially when topics include noise or ambiguous terms. Some guardrails that could help improve the results of the AI-generated labels include preprocessing LDA keywords to remove irrelevant words and prompt engineering by including topic-specific dictionaries to aid in label generation.

Alone, the AI-generated labels still require final human review before they can be reliably used in archives, as some topics contain ambiguous or irrelevant terms that the AI may misinterpret. However, using a combination of manual LDA topic modeling and AI-generated labels can be highly effective. LDA identifies latent patterns and co-occurring terms across a large corpus, while AI provides interpretable labels. Together, these approaches allow archivists to efficiently surface, interpret, and tag prominent themes in a collection, improving both scalability and usability while still ensuring accuracy through human oversight.

An Asian American Poem on Defying American Standards
This poem is written by June Lagmay and published in the February 1978 issue of the Pacific Ties Newsmagazine. In the poem, the Asian American speaker describes their initial attempts to fit into the American culture by altering their hair and facial features to look more like their Caucasian counterparts. The speaker then describes their ancestors and shows admiration for how they proudly embraced their culture. The poem concludes with defiance against trying to conform to American culture and with a confident proclamation to keep and uphold their own appearance and culture.
The poem shares a significant part of the lived experience within the ADIPA community: identity formation and the struggles of dealing with the pressure of assimilation to American culture. Other works in the archive also spotlight the thoughts, feelings, and emotions of marginalized voices, allowing present readers to learn about and connect with the stories from previous generations.
June Lagmay was born in Yokohama, Japan in 1954 and grew up in Los Angeles. She graduated from UCLA with a degree in Sociology in 1976. Lagmay’s career was centered around social activism for the LGBTQ+ community and the APIDA community. Notably, in 2009, she was appointed by the Los Angeles mayor and confirmed by the L.A. City Council as the Los Angeles City Clerk. She is known as the first Asian-American and LGBTQ+ person to hold this office in L.A. history. In 2014, she was honored as a Woman of the Year by the organization API Equality with decades of human rights activism, and as a City Legend and Leader in the LGBTQ+ Community by the L.A. City Council.
computer vision Image Tagging: human vs. gemini
Using the AI LLM Gemini as a computer vision tool to tag images may not be adequate enough to use in archives due to the tendency for inaccuracy. We used code in Google Colab to prompt Gemini to tag the illustration that accompanies the “Poem” piece by June Lagmay in the February 1978 issue of the Pacific Ties Newsmagazine. We first manually came up with 5 single-word tags for the image. Our tags were “woman, hair, headband, face, and portrait”. We then uploaded our image into Google Colab and ran our Gemini code. It produced these 5 AI-generated tags: “woman, illustration, hat, stylized, and portrait”.
To make a comparison between the manual tags and the AI-generated tags of the image, we ran code to calculate the Jaccard similarity score. The Jaccard similarity score is a method that compares how closely two sets overlap by counting the number of unique elements that two lists share. The resulting score was 0.25, because two out of the five words were the same between the two lists of tags. The AI tag “stylized” is not a very helpful tag compared to the others because it’s a vague adjective. Additionally, the AI tag “hat” is not accurate to the image because the woman is wearing a headband-style accessory. However, the AI tags of “woman”, “illustration”, and “portrait” were accurate.

The low Jaccard similarity score and some relatively inaccurate tags suggest that AI computer vision tools may not be fully ready to use in archival projects. To improve the accuracy of the AI output, some guardrails can be set to produce more specific tags. For example, we could add additional guidelines in the prompt to instruct it to not produce adjectives, thus preventing AI tags like “stylized” or other vague adjectives.

UCLA’s 1978 Chinese new year celebration events
This article is written by Cary Wong and published in the February 1978 issue of the Pacific Ties Newsmagazine. Wong describes the UCLA Chinese Lunar New Year celebrations that took place during the week of January 25-28. The events hosted by the Chinese Cultural Association sought to increase awareness and understanding of Chinese culture among the UCLA community. The Lunar New Year celebrations began with a lion dance and kung-fu demonstration at Royce Hall, an arts and crafts exhibition in the Ackerman Union, and a painting and calligraphy demonstration. Other events included an acupuncture program, a Chinese Film Festival, a cooking demonstration, a folk dance and music demonstration, and a cultural variety show. Throughout the article, Wong consistently describes the high turnout and how many people enjoyed all of the events. By writing about these past cultural events in a newsmagazine article, it preserves the history of Asian American cultural celebrations at UCLA.
Today, the American Chinese Association (ACA) and various other Asian American cultural organizations at UCLA host similar cultural festivities to celebrate Lunar New Year. This continuity after several decades illuminates the strength of cultural advocacy and the importance of preserving traditions among the ADIPA community.
By documenting historical and cultural APIDA events like those hosted by the Chinese Cultural Association in 1978, future generations of APIDA youth can take inspiration from these celebrations and incorporate them into their own. This article is one of many throughout the archive that aims to spread awareness of APIDA student advocacy and empowers others to continue building community through such events.
sentiment analysis: vader vs. gemini
The AI LLM Gemini may be ready to use in archival projects to perform sentiment analysis on a given text. We performed sentiment analysis on Cary Wong’s article “UCLA Celebrates Chinese New Years” by using two tools. The first tool involved Python code that used Valence Aware Dictionary and sEntiment Reasoner (VADER) from the NLTK library, and the second tool involved Python code in Google Colab to prompt Gemini. We inserted the text from the article into both tools and had them produce outputs with polarity scores of positive, negative, and neutral, along with the compound sentiment score.
VADER’s sentiment analysis of the article indicated an overall very positive sentiment, with a compound score of 0.9972. The polarity scores are as follows: negative: 0.037, neutral: 0.837, positive: 0.126. The majority of the article’s text was detected as neutral, but the overall normalized sentiment was highly positive. Furthermore, we gave the following prompt to Gemini: “Perform a sentiment analysis of the following text, providing polarity scores for positive, neutral, and negative. Also, provide a compound sentiment score to summarize all three scores.” Similarly, Gemini’s sentiment analysis of the article indicated an overwhelmingly positive sentiment, with a compound score of 0.998. The polarity scores were as follows: negative: 0.000, neutral: 0.744, positive: 0.256. Interestingly, Gemini’s negative polarity score was 0.000 while VADER’s negative score was 0.037. A helpful advantage of using Gemini to perform sentiment analysis is that the output includes a detailed explanation behind each score. Gemini explains that they gave a negative polarity score of 0.000 because there were no words or phrases in the text that conveyed negativity. Gemini also gave a compound score of 0.998 because the strong positive score outweighed the neutral score.
The AI LLM seemed to have performed the task accurately because we could verify the scores through the provided explanations in the output. This explanation portion that VADER lacks may make Gemini a more helpful tool for sentiment analysis because we could easily verify the credibility of the scores. Thus, AI tools like Gemini may be helpful to use in archives to perform sentiment analysis because it can provide an explanation or reasoning behind their resulting scores. A notable guardrail to using AI is to make sure to specify in the prompt that it should provide polarity scores and a compound score instead of solely a qualitative description.

Bakke, An Asian Perspective


Asian american perspective on supreme court ruling
This opinion article talks about the stereotypes and prejudices that Asian-Americans and Black-Americans face in daily life. This article is written by John Ohashi and was published in the February 1978 issue of the Pacific Ties Newsmagazine. Ohashi calls attention to the Bakke v. Regents of the University of California case where Bakke was denied support by the fourteenth amendment, and claimed preferential treatment of racial minorities working against him for admission into the first year medical class at UC Davis. The two page article delves into the multi-faceted conversation of this supreme court ruling from an Asian perspective. This article continues the message that student publications hold value in that they spotlight underrepresented perspectives in traditional mass media. While major news outlets may have covered the ruling of this case, it is unlikely that in depth coverage would be provided to supplement the initial coverage.
Sentiment analysis: Vader vs. gemini
Gemini may be ready to use in archival projects to perform sentiment analysis on a given text. We performed sentiment analysis on John Ohashi’s article “Bakke, An Asian Perspective” by using two tools. The first tool involved Python code that used Valence Aware Dictionary and sEntiment Reasoner (VADER) from the NLTK library, and the second tool utilized Python code in Google Colab to prompt Gemini. We inserted the text from the article into both tools and had them produce outputs with polarity scores of positive, negative, and neutral, along with the compound sentiment score.
VADER’s sentiment analysis of the article provided an overall very positive sentiment, with a compound score of 0.9972. The polarity scores are as follows: negative: 0.058, neutral: 0.853, positive: 0.089. The majority of the article’s text was detected as neutral, but the overall normalized sentiment was highly positive, despite being rather critical in nature. We prompted Gemini by asking it to: “Perform a sentiment analysis of the following text, providing polarity scores for positive, neutral, and negative. Also, provide a compound sentiment score to summarize all three scores.” In contrast to VADER, Gemini’s sentiment analysis of the article indicated an extremely negative sentiment, with a compound score of -0.9935. The polarity scores were as follows: negative: 0.240, neutral: 0.0.43, positive: 0.0117. Gemini’s negative polarity score was 0.0.240 while VADER’s negative score was 0.0.058, which is a drastic difference by comparison. Using Gemini to perform sentiment analysis presented an advantage that includes a detailed explanation behind each score. Gemini explains that they gave a negative polarity score of 0.240 because of the strong critique of the Supreme Court decision, among other phrasing and negatively connotative vocabulary utilized.
Gemini seemed to have performed the task mostly accurately because we could verify the scores through the provided explanations in the output. This explanation portion provided by Gemini makes it a more helpful tool for sentiment analysis due to easier verification of the credibility of the scores produced. Therefore, AI tools like Gemini may be helpful to use in archives to perform sentiment analysis as it can provide an explanation or reasoning behind the produced scores. A guardrail to using AI is to make sure to specify in the prompt that it should provide polarity scores and a compound score instead of solely a qualitative description. In addition, it is imperative to be familiar with the content being analyzed to understand the nature of the content in terms of sentiment. This artifact was highly critical, but both VADER and Gemini seemed to have tagged most of the content as neutral, but only Gemini provided a negative compound score, signifying the artifact as nearly completely negative.


attitudes on Korean american third spaces
This article highlights the significance and importance of the Korean Youth Center in providing a third space for Korean-American youth to aid in assimilating into American culture. This article was written by Kim Lim and was published in the February 1978 issue of the Pacific Ties Newsmagazine. Lim describes how the Korean Youth center is a hub for personal development and provides services that aid the community in their struggles with assimilation, namely counseling and drug abuse prevention programs with the goal of upholding Korean identity in America.
The article makes no effort to sugarcoat problems the community is facing due to struggles with finding home in a new country, looking to the resources the KYC offers to all–especially its youth. These resources underscore the mission of provide a great deal of support to those that need it, including families of Korean Americans, as well as non-Korean community members, continuing the narrative that solidarity is what drives communities and society forward.
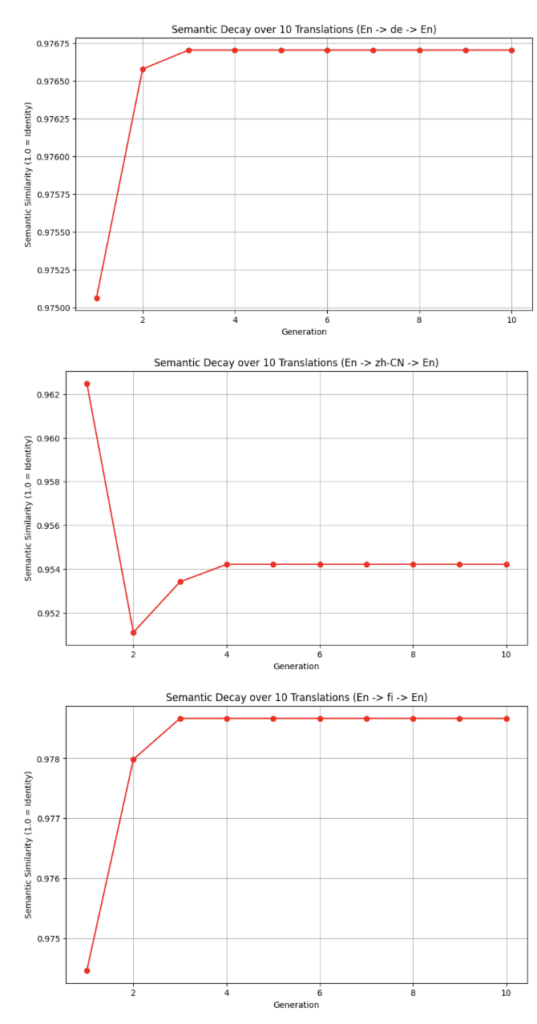
Translation: SBERT vs Google Translate
Using the SBERT and Google Translate as translation tools may be useful for digital archives with high accuracy in translating to and from English given a target language. We used code in Google Colab to translate our text back and forth to and from English, and measure the change in meaning according to the sentence transformer. We use cosine similarity to measure how different the two vectors are after 10 translations, capturing semantic decay after each translation. We translated the text of the article by Kim Lim, “The Korean Youth Center is OKAY for The Korean One,” into German, Simplified Chinese, and Finnish.
To compare the differences across languages we ran code to translate the article into each target language, with comparison scores ranging from 0.0 to 1.0, with higher scores representing a more accurate translation with little semantic decay. The German translation produced an initial score of 0.9751, followed by a score of 0.9766 for the remaining translations. The Simplified Chinese analysis provided an initial score of 0.9625, followed by 0.9511, 0.9534, and then 0.9542 for the remaining translations. The Finnish translation produced an original score of 0.9745, followed by 0.9780, then 0.9787 for the remaining translations.
While these scores seemed to all have had some variation in accuracy, they all remained above a 0.95 score at minimum, signifying that SBERT is a useful tool that can produce accurate translations with little semantic decay after 10 translations. Although the data shows that there is some semantic loss, this is a metamessage that its usefulness can only do so much.
While these translations by SBERT provided high scores, they were not perfect. This is why human translation is necessary to employ in supplement to SBERT or Google Translate. With the help of SBERT, the gaps in its use can be reduced, where human knowledge and context are crucial for more accurate translation. We only saw how SBERT works with three languages, meaning there is more to explore with other languages that may not be similar to English. Our analysis with Simplified Chinese provided a rather high score, despite not being an alphabetic language, signaling how SBERT can be useful regardless of language type, but with human context of culture and language, can be the most effective.